Devanagari
| Devanagari | |
 Rukopis Rigveda Devanagari (počátek XIX th století). | |
| Vlastnosti | |
|---|---|
| Typ | Alfanumerické |
| Jazyk (y) | Některé jazyky severní Indie , včetně sanskrt , hindština , Marathi , Sindhi , Bihari , Bhili , Konkani , Bhojpuri , nepálské , Névárština a někdy kašmírského |
| Historický | |
| Čas | XII th století až do dneška |
| Systém (y) rodič (é) |
Protosinaitický |
| Kódování | |
| Unicode | U + 0900 až U + 097F |
| ISO 15924 | Deva |
Devanagari je sanskrtské देवनागरी ( devanagari ) je psaní alphasyllabaire používá sanskrtu , v Prakrit , v hindštině , The Nepálci , v Marathi a několika dalších indických jazyků . Je to jeden z nejpoužívanějších skriptů v severní Indii a Nepálu .
Dějiny
Původ
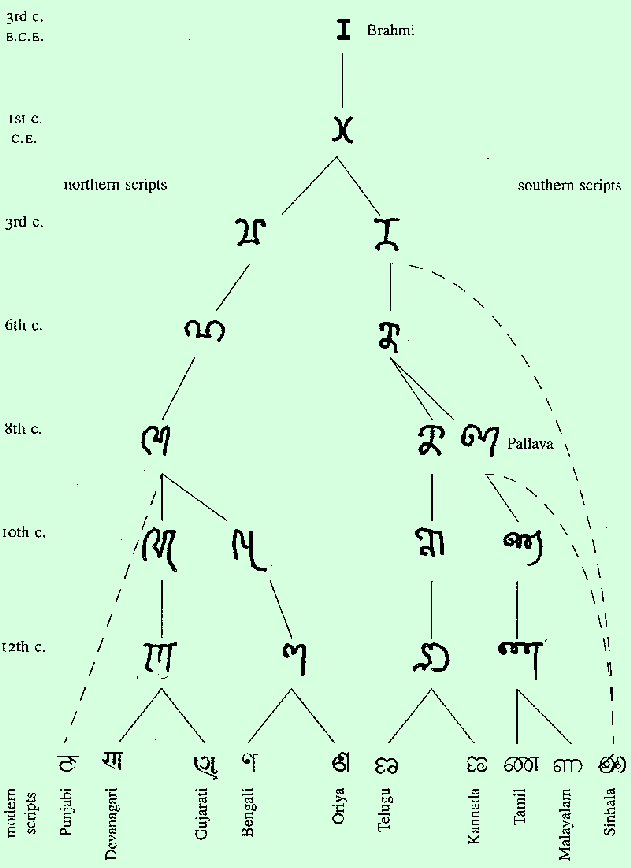
Jako téměř všechna indická písma, i Devanagari pochází z písma Brahmi , přesněji z písma Gupta .
To stopuje původy Devanagari kolem XII -tého století , pravděpodobně jako modifikace Siddham . Postupně nahradil skript sharda ve velké části severní Indie.
Devanagari je nyní jedním z nejpoužívanějších skriptů v Indii a používá se převážně k psaní hindštiny , zdaleka nejrozšířenějšího jazyka v Indii. Hindština psaná v Devanagari je také oficiálním jazykem Indie, takže je nepálská napsána v Devanagari, „jazyce národa“ Nepálu . Toto psaní se také používá k psaní, mimo jiné, Marâthî a Sindhi . Tradičně v severní Indii byl s ní psán sanskrt .
Méně mluvené jazyky jsou také pomocí tohoto zápisu: Bihari se Bhili Konkani bhodjpuri na Névárština . Kašmírové někdy také využívají devanagari, ačkoli používá hlavně arabskou abecedu v upravené podobě.
Etymologie
Termín devanagari pochází ze sanskrtu. Rozkládá se na:
- देव ( deva ): božský;
- नागरी ( nāgarī ): ženský rod नागर ( nāgara ), obyvatel města.
Toto slovo proto kvalifikuje toto psaní jako „obyvatele božského města“. Název lze také zkrátit jako „ nagari “.
Hlavní rysy
Devanagari je psán vodorovně, zleva doprava, nerozlišuje velká a malá písmena. Pozná se to podle souvislého vodorovného pruhu („šibenice“, „ hlavní linie “), pod kterou jsou znaky připojeny. U některých znaků otevřených nahoře se tato lišta krátce pozastaví. V moderních jazycích je také přerušován mezi slovy, ale v případě sloučenin a sandhi může v sanskrtu překlenout několik slov za sebou . V rukopisu je lišta nakreslena po napsání celého slova.
Nyní používá stejná interpunkční znaménka jako latinská abeceda , s výjimkou někdy konců veršů a vět v tradičním psaní. U některých postav existují varianty.
Jedná se o téměř fonetické psaní, kdy symbol vždy představuje stejný foném , i když existují rozdíly mezi jednotlivými jazyky nebo dialekty . Základní jednotka - zvaná akshara (ze sanskrtského अक्षर ( akṣara ), což znamená „písmeno, znak“) - se skládá ze seskupení jedné nebo více po sobě jdoucích souhlásek, za nimiž případně následuje samohláska , nebo samohláska. Když samohláska sleduje souhlásku, je reprezentována diakritikou připojenou k této souhláse. Když několik souhlásek následuje za sebou, jsou reprezentovány ligaturou. Akshara je často, ale ne vždy, je slabika slova.
Omezení prezentace
Vodorovný pruh, pod kterým je napsána většina základních písmen, je graficky spojen s vodorovnými pruhy předcházejících a následujících základních písmen, pokud mají jedno. Při zarovnávání textu je povoleno prodloužit mezery mezi písmeny aksharas a zachovat toto grafické spojení, které identifikuje slova. Ale grafická forma akshary obvykle zůstává nezměněna (zejména vertikální poloviční glyfová danda , spojená graficky napravo od určitých plných písmen a která graficky představuje implicitní samohlásku v plném písmenu, se nesmí odchýlit od polovičního glyfu představujícího odpovídající mrtvé písmeno).
Vzhledem k tomu, aksharas vymezují slabiky, dělení slov je povoleno téměř kdekoli ve slově mezi dvěma aksharas . Aby však toto dělení respektovalo fonetické nebo sémantické slabiky, devanagari umožňuje přepsat skupinu souhlásek na dvě odlišné části tím, že nutí poslední souhlásku první skupiny přijmout úplnou formu výslovně zbavenou přidružené samohlásky, ale přes všechno oddělitelné. V tomto případě tato skupina souhlásek logicky souvisí s předchozí akšarou zakončenou samohláskou, jako by to byly konečné souhlásky, a dělení slov v tomto případě nebude povoleno před touto skupinou souhlásek.
Příklad
Text v devanagari ( hindský jazyk ) सभी मनुष्यों को गौरव और अधिकारों के मामले में जन्मजात स्वतन्त्रता और समानता प्राप्त है। उन्हें बुद्धि और अन्तरात्मा की देन है और परस्पर उन्हें भाईचारे के भाव से बर्ते Přepis textu v latince ( IAST ) Sabhī manuṣyoṃ ko gaurav aur adhikāroṃ ke māmle meṃ janmajāt svatantratā aur samāntā prāpt hai. Unheṃ buddhi aur antrātmā kī den hai aur parspar unheṃ bhāīcāre ke bhāv se bartāv karnā cāhiye. francouzský překlad Všichni lidé se rodí svobodní a rovní v důstojnosti a právech. Jsou obdařeni rozumem a svědomím a musí jednat vůči sobě navzájem v duchu bratrství.alphasyllabaire
Devanagari písmo zásadně odlišuje samohlásky od souhlásek ve fungování jejich reprezentace.
Samohlásky
Samohláska může být vyjádřen dvěma různými znaky v závislosti na tom, zda následuje souhlásky (závislá forma) nebo ne (samostatným):
- v prvním případě je závislá samohláska reprezentována diakritikou - zvanou matra (मात्रा) - kterou lze spojit doprava, doleva, pod nebo nad souhláskou, po které se vyslovuje;
- v druhém případě je samostatná samohláska plnohodnotnou akšarou .
(Mnoho glyfů má velmi odlišnou výslovnost v různých jazycích. Jsou prezentovány znakem „/“ oddělujícím varianty.)
| Nezávislá samohláska | Samohláska závislá po प | Transkripce | Výslovnost ( API ) |
|---|---|---|---|
| अ | Alone (sám) | na | [ ɐ ] / [ ǝ ] / [ ɔ ] / [ o ] / [ ɵ ] |
| आ | .ा | na | [ ɑː ] / [ a ] |
| इ | पि | i | [ i ] / [ ɪ ] |
| ई | पी | ī | [ iː ] / [ i ] |
| उ | पु | u | [ u ] / [ ʊ ] |
| ऊ | पू | ū | [ uː ] / [ u ] |
| ऋ | पृ | ŕ | ɻ / ɾi / ru |
| ॠ | पॄ | ṝ | ɹː / ruː |
| ऌ | पॢ | ḷ | l̩ / li / lru |
| ॡ | पॣ | ḹ | l̩ː / liː / lruː |
| ऍ | पॅ | E | [ ɛ ] |
| ऎ | पॆ | E | [ ě ] |
| ए | .े | e / ē | [ eː ] / [ e ] / / [ ɛ ] / [ æ ] / [ aĭ ] |
| ऐ | पै | mít | [ ɛ ] / [ əɪ̆ ] / [ ɑɪ̆ ] / [ eː ] / [ ːː ] / [ oɪ̆ ] / [ ɔɪ̆ ] / [ ɵĭ ] |
| ऑ | पॉ | Ach | [ ɔ ] |
| ऒ | पॊ | Ó | [ ŏ ] |
| ओ | पो | o / ó | [ oː ] / [ o ] / [ ʊ ] / [ aŭ ] |
| औ | पौ | na | [ ɔ ] / [ əŭ ] / [ aŭ ] / [ oː ] / [ ɵŭ ] / [ oŭ ] / [ ɔŭ ] |
Samohlásky [u] a [uː] nejsou psány obvyklými matracemi, když následují izolované र:
| Nezávislá samohláska | Závislá samohláska |
|---|---|
| उ | रु |
| ऊ | रू |
Existuje několik případů nasalizace souhlásky nebo samohlásky, které lze vykreslit:
- buď bindu (बिन्दु), bod výše (například s अ: अं)
- buď candrabindu (चन्द्रबिन्दु) bod převyšující půlměsíc (zde s अ: अँ)
Když se první souhlásky kombinace je nosní a následuje souhlásky stejné třídy artikulační , může být reprezentována bindu umístěného na předcházející Akshara . Tato nasalizace se nazývá anusvara ( अनुस्वार ). Před ह anusvara představuje velar nosní (api [ŋ]). Labiální म tedy může být zobrazen jako anusvara, když předchází labiální ब, zubní न, když předchází zubní त nebo स atd. V sanskrtu je samohláska předcházející bindu také nasalizovaná, ale ne v hindštině / urdštině.
| Před | anusvara znamená | Příklad | |
|---|---|---|---|
| Velární | क, ख, ग, घ nebo ह | ङ | पंखा = पङ्खा |
| Palatals | च, छ, ज nebo झ | ञ | शतरंज = शतरञ्ज |
| Retroflexy | ट, ठ, ड nebo ढ | ण | गुंडा = गुण्डा |
| Zuby | त, थ, द, ध, ल nebo स | न | अंतर = अन्तर |
| Lékovky | प, फ, ब nebo भ | म | संभव = सम्भव |
Samohláska nasalization se nazývá anunasika (अनुनासिक). Je vykreslen bindu nebo candrabindu . V moderní hindštině se candrabindu používá jen zřídka a samotný bindu je téměř systematický. Řešením, které se někdy používá, je použití candrabindu, když není akshara překonána žádným znamením, bod pouze tehdy, když je slabičný graf doprovázen matrou . V tomto případě jde o bod napravo od něj.
| Nezávislá nenasalizovaná samohláska | Nasalized nezávislá samohláska | Samohláska závislá po प |
|---|---|---|
| अ | अँ | पँ |
| आ | आँ | पाँ |
| इ | इँ | पिंँ (पिं) |
| ई | ईं | पीँ (पीं) |
| ए | एँ | पेँ (पें) |
| ओ | ओं | पोँ (पों) |
Příklad rozlišení anusvara / anunasika
- Hindština: पंचम [pɐɲc͡çɐm] / पाँचवाँ [pãc͡çβ̞ã]
- Sanskrt: हंस [hɐ̃ns] / हँस [hɐ̃snɐ̙ː]
Devanagari má za diakritikou umístěnou další diakritiky:
| Diacritic (zde po ए) | Označení | Funkce |
|---|---|---|
| एऽ | avagraha (अवग्रह) | používá se k prodloužení zvuku samohlásky (v Marâthî značka výslovně označuje neelise implicitní samohlásky na konci slova, přičemž tato elise je obecně implicitní a neoznačená) |
| एः | visarga (विसर्ग) | je hluchý [ h ]. Nejčastěji se vyslovuje jako barevný [ h ] z předchozí tlumené samohlásky. |
Souhláska
Pokud souhláska není přímo předcházena ani bezprostředně následována jinou souhláskou, je reprezentována základním symbolem (úplná forma). V tomto případě to je vyslovováno následované implicitní samohláskou [ ə ], nebo někdy vyslovováno bez samohlásky vůbec, v některých případech v jazycích, jako je hindština. Mnoho souhláskových glyfů má svislou čáru zvanou danda .
Pokud za souhláskou následuje sanskrtská diacritická virama ( विराम ), žádná samohláska se nevyslovuje . Tato značka je připojena pod finální Danda plné souhláskou, nebo na střed níže, pokud znamení plného souhlásky nezahrnuje Danda : क् (zde doprovodný क). V hindštině se tomu říká halant ( हलन्त ) .
Devanagari rozlišuje mezi nasávanými a nenasátými okluzivními souhláskami a dentály od retroflexů .
| Plosives | Non-plosives | |||||||
|---|---|---|---|---|---|---|---|---|
| Hluchý | Zvuk | Nosní | Sonantes | Fricatives | Boční spirant | |||
| není nasáván | naštvaný | není nasáván | naštvaný | |||||
| Velars | क [ k ] (k) | ख [ K ] (kh) | ग [ ɡ ] (g) | घ [ ɡʱ ] (gh) | ङ [ ŋ ] (ṅ) | |||
| Palatals | च [ c͡ç ] (c) | छ [ c͡çʰ ] (ch) | ज [ ɟ͡ʝ ] (j) | झ [ ɟ͡ʝʱ ] (jh) | ञ [ ɲ ] (ñ) | य [ j ] (y) | श [ ç ] (ś) | |
| Retroflexy | ट [ ʈ ] (ṭ) | ठ [ ʈʰ ] (ṭh) | ड [ ɖ ] (ḍ) | ढ [ ɖʱ ] (ḍh) | ण [ ɳ ] (ṇ) | र [ r ] (r) | ष [ ʂ ] (ṣ) | ळ [ ɭ ] (ḷ) |
| Zuby | त [ t̪ ] (t) | थ [ t̪ʰ ] (th) | द [ d̪ ] (d) | ध [ d̪ʱ ] (dh) | न [ n ] (n) | ल [ l ] (l) | स [ s ] (s) | |
| Lékovky | प [ p ] (p) | फ [ pʰ ] (ph) | ब [ b ] (b) | भ [ b ] (bh) | म [ m ] (m) | व [ β̞ ] (v) | ||
| Globální | ह [ ɦ ] (h) | |||||||
Když slovo končí akšarou převyšovanou anusvarou, která neslouží k nasalizaci samohlásky, představuje tato anusvara म्. Například ग्रामं = ग्रामम्.
Nové souhláskyK přepisu nepůvodních zvuků devanagari a dalších zvuků, které v sanskrtu neexistovaly , se některé souhlásky odebírají z bodu zvaného nuqtā .
| Symbol | Transkripce | Výslovnost ( API ) |
|---|---|---|
| क़ | q | [ q ] |
| ख़ | X | [ x ] |
| ग़ | G | [ ʀ ] |
| ज़ | z | [ z ] |
| ड़ | ŕ | [ ɽ ] |
| ढ़ | jé | [ ɽʱ ] |
| फ़ | F | [ f ] |
Kombinace
Když je vysloveno několik souhlásek v řadě (bez mezilehlé samohlásky), devanagari používá kombinace souhlásek, které seskupují několik souhláskových symbolů tvořících ligaturu . Může to být buď jednoduchá grafická komprese souhlásek připojených k sobě, nebo zcela nový glyf . Lze jej doplnit samohláskou ve formě klasické matry, která platí pro celou vytvořenou kombinaci. Obvaz vyplývající z kombinace a její možné samohlásky tvoří akshara .
Kombinace může být také reprezentována jednoduchým připojením viramy k první souhlásce.
Seskupení vpravoV nejjednodušším obecném případě, kdy je první souhláska (v plné formě) ohraničena napravo dandou , je kombinována s druhou tak, že ztratí svou dandu a drží se další. Stejným způsobem क a फ vidí jejich atrofovanou pravou končetinu.
| 1 re souhlásky | 2 e souhláska | Kombinace |
|---|---|---|
| स | त | स्त |
| ब | द | ब्द |
| ष | य | ष्य |
| क | य | क्य |
| फ़ | त | फ़्त |
V některých případech je atrofována druhá souhláska kombinace, první si zachovává původní podobu. Takže když द je první souhláska kombinace, druhý obvykle lepí až po jeho levé straně poté, co ztratil svou Danda . I když je ohraničena dandou , může mít zvláštní podobu - sama ohraničenou dandou - když je první kombinací a druhá souhláska je व, र, च nebo न, druhá souhláska se poté přichytí na dno po jeho levici. Lze však také najít obvyklou formu s jednoduchou nepřítomností dandy . Na první pozici kombinace ह přijímá následující souhlásku vlevo dole, jinak se otevírá zprava.
| 1 re souhlásky | 2 e souhláska | Kombinace |
|---|---|---|
| द | व | द्व |
| द | ध | द्ध |
| श | व | श्व |
| ह | म | ह्म |
| ह | व | ह्व |
Souhláska र má velmi konkrétní formy v kombinacích.
Pokud následuje souhlásku s dandou v její plné podobě, र je obvykle reprezentována jako šikmý segment visící vlevo dole na dandě . Když tato předchozí souhláska nezahrnuje dandu , र je reprezentována ve formě spojeného šikmého segmentu připojeného pod předchozí souhlásku v plné formě (pokud tato obsahuje dandu, kde je tento segment připevněn bočně), nebo dvou šikmých segmentů spojených shora a připojený pod předchozí souhláskou v plné formě (bez dandy ).
Když र předchází další souhlásku, je reprezentována jako oblouk kruhu zakřiveného vpravo, umístěný v pravém horním rohu akshary (tj. Skupina souhlásek, která následuje a která může - dokonce vytvářet ligaturu nebo být doprovázena závislou samohláska), ke kterému patří.
| 1 st díl | 2 e část | Kombinace |
|---|---|---|
| क | र | .्र |
| प | र | .्र |
| ग | र | .्र |
| ट | र | .्र |
| र | त | र्त |
| र | .ा | र्चा |
| र | र | Kromě toho |
Nakonec existují určité kombinace, pro které jsou počáteční tvary velmi upravené nebo dokonce neviditelné.
| 1 re souhlásky | 2 e souhláska | Kombinace |
|---|---|---|
| त | त | त्त |
| त | र | .्र |
| क | त | क्त |
| द | द | द्द |
| द | य | द्य |
| द | म | द्म |
| ज | ञ | ज्ञ |
| क | ष | क्ष |
Tradiční skript Devanagari používá stovky těchto specifických ligatur, ale žádný z nich není pro čtení nezbytný, pokud je dobře zastoupeno znamení virama umožňující rozlišení mezi mrtvými a živými souhláskami.
Další symboly a interpunkce
| Symbol | Označení | Funkce |
|---|---|---|
| । | danda (दण्ड), (khadi) pai (खड़ी पाई) nebo purna virama (पूर्ण विराम) | označí konec řádku v poezii nebo náboženském textu nebo konec věty |
| ॥ | dvojitá danda | konec odstavce nebo značka sloky v poezii |
| ॰ | symbol zkratky umístěný za aksharou | |
| ॐ | Om̐ | Hinduistický posvátný symbol Om̐ |
| प॑ | udatta (उदात्त) | zdůraznění výslovnosti určitých sanskrtských textů |
| प॒ | anudatta (अनुदात्त) | zdůraznění výslovnosti určitých sanskrtských textů |
Čísla
Ačkoli se devanagari používá stále častěji s arabskými číslicemi , má pro tyto symboly vlastní symboly:
| Šifra devanagari | ० | १ | २ | ३ | ४ | ५ | ६ | ७ | ८ | ९ |
|---|---|---|---|---|---|---|---|---|---|---|
| Arabská číslice | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Jsou vypůjčené od brahmi .
Varianty
Kromě nepatrných estetických rozdílů v některých případech dochází u devanagari k významným odchylkám ve znázornění symbolů अ, आ, ओ, औ, ण a झ.
| Běžná forma | Alternativní forma |
|---|---|
 |

|
 |
|
 |
|
 |
|
 |

|
 |

|
 |

|
Lexikografický řád
Stejně jako latinská abeceda následuje abecední pořadí, devanagari následuje pořadí, zejména používané ve slovnících .
Nejprve máme samohlásky v pořadí अ , आ , ॲ , ऑ , इ , ई , उ , ऊ , ऋ , ॠ , ऌ , ॡ , ए , ऐ , ओ , औ , poté známky nasalizace ( anusvara nebo candrabindu ) následuje visarga, a konečně souhlásky v pořadí क , ख , ग , घ , ङ , च , छ , ज , झ , ञ , ट , ठ , ड , ढ , ण , त , थ , द , ध , न , प , फ , ब , भ , म , य , र , ल , व , श , ष , स , ह . Souhláska označená nuqta bezprostředně následuje neoznačenou souhlásku.
Počítačové kódování
Alphasyllabary je v Unicode reprezentován následujícími bloky:
|
PDF: en |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | NA | B | VS | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U + 0900 | कऀ | कँ | कं | कः | ऄ | अ | आ | इ | ई | उ | ऊ | ऋ | ऌ | ऍ | ऎ | ए |
| U + 0910 | ऐ | ऑ | ऒ | ओ | औ | क | ख | ग | घ | ङ | च | छ | ज | झ | ञ | ट |
| U + 0920 | ठ | ड | ढ | ण | त | थ | द | ध | न | ऩ | प | फ | ब | भ | म | य |
| U + 0930 | र | ऱ | ल | ळ | ऴ | व | श | ष | स | ह | कऺ | कऻ | क़ | ऽ | .ा | कि |
| U + 0940 | की | कु | कू | कृ | कॄ | कॅ | कॆ | .े | कै | कॉ | कॊ | को | कौ | क् | कॎ | कॏ |
| U + 0950 | ॐ | क॑ | क॒ | क॓ | क॔ | कॕ | कॖ | कॗ | क़ | ख़ | ग़ | ज़ | ड़ | ढ़ | फ़ | य़ |
| U + 0960 | ॠ | ॡ | कॢ | कॣ | । | ॥ | ० | १ | २ | ३ | ४ | ५ | ६ | ७ | ८ | ९ |
| U + 0970 | ॰ | ॱ | ॲ | ॳ | ॴ | ॵ | ॶ | ॷ | ॸ | ॹ | ॺ | ॻ | ॼ | ॽ | ॾ | ॿ |
|
PDF: en |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | NA | B | VS | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U + A8E0 | क꣠ | क꣡ | क꣢ | क꣣ | क꣤ | क꣥ | क꣦ | क꣧ | क꣨ | क꣩ | क꣪ | क꣫ | क꣬ | क꣭ | क꣮ | क꣯ |
| U + A8F0 | क꣰ | क꣱ | ꣲ | ꣳ | ꣴ | ꣵ | ꣶ | ꣷ | ꣸ | ꣹ | ꣺ | ꣻ | ꣼ | ꣽ | ꣾ | कꣿ |
Tibetský
Thönmi Sambhóta , ministr Songtsen Gampo je 33 rd král Tibetu by vytvořil tibetský skript z indického abecedy devanagari. Podle Eugèna Burnoufa je tibetské písmo blíže starověkým devanagari než současným devanagari.
Reference
Poznámky
- Není-li stanoveno jinak, použije-li se přepis k vyúčtování písmen devanagari s písmeny latinské abecedy , použije se doporučení Wikipedie o přepisu indických jazyků.
- Tento skript se však již dlouho používá k zaznamenávání kašmírského jazyka .
- Není to však jediný indický skript, který má tuto vlastnost.
Reference
- (en) Chronologie stránky University of Colorado
- Unicode Consortium , „ Kódy pro reprezentaci jmen skriptů “, na unicode.org ,1 st 05. 2004(zpřístupněno 12. října 2007 )
- Výrazné \ de.va.na.ɡa.ʁi \ (viz wikt: devanagari ). Také někdy psaný 'dévanagari' ve francouzštině nebo, variabilně podle přepisu, 'devanāgarī', 'devanâgarî', dokonce 'dévanâgarî'.
- Coulmas 2003 , str. 136
- Coulmas 2003 , str. 150
- (en) Úřad generálního tajemníka, Indie, „ Census of India “ ( archiv • Wikiwix • Archive.is • Google • co dělat? ) ,1991(zpřístupněno 12. října 2007 )
- Indian ústava, citovaný v (en) indické vlády, " Unie: oficiální jazyk " ( Archiv • Wikiwix • Archive.is • Google • Co dělat ) (přístup 12.10.2007 ) .
- (in) Birendra Bir Bikram Shah Deva , „ Nepalese Constitution “ ( Archiv • Wikiwix • Archive.is • Google • Co dělat? ) (Přístup 12. října 2007 ) , s. 1
- deva v Huet 2007
- nāgara v Huet 2007
- Montaut a Joshi 1999 , str. 19
- Snell 2003 , str. 5
- Montaut a Joshi 1999 , s. 27
- Coulmas 2003 , str. 140
- Montaut a Bakaya 1994 , s. XXVIII
- Snell 2003 , str. 16
- akṣara v Huetu 2007
- Coulmas 2003 , str. 134
- Opravená verze k dispozici v Coulmas 2003 , str. 243.
- Coulmas 2003 , str. 131
- Bahri 2004 , s. (xi)
- Montaut a Joshi 1999 , str. 22
- Federica Boschetti, francouzský hindský slovník , Paříž, Éditions du Makar,1994, 382 s. ( ISBN 2-9506068-2-2 ) , str. 4
- Montaut a Joshi 1999 , str. 25
- Bahri 2004 , str. (xii)
- Montaut a Joshi 1999 , s. 24-25
- Montaut a Bakaya 1994 , str. XXXI
- દવે a kol. 2006 , s. 61
- Montaut a Bakaya 1994 , s. XXXVII
- Coulmas 2003 , str. 138
- Montaut a Joshi 1999 , str. 19-21
- Montaut a Joshi 1999 , s. 21-22
- (in) K. Machida, „ Klasifikace konjunktních glyfů Devanagari Script “ na aa.tufs.ac.jp ,2006(zpřístupněno 12. října 2007 )
- Bahri 2004 , str. (xvi)
- દવે a kol. 2006 , s. 60
- Montaut a Joshi 1999 , s. 26
- (en) Unicode Consortium , „ Znaky Unicode pro devanagari “ , na unicode.org ,2006(zpřístupněno 12. října 2007 ) ,s. 3
- Montaut a Joshi 1999 , str. 23
- Montaut a Joshi 1999 , str. 23-24
- Bahri 2004 , s. (xv)
- Montaut a Bakaya 1994 , s. XXXVI
- Bahri 2004 , s. 385
- (ahoj) પ્રો. શ્રી રામચંદ્ર શર્મા, परफेक्ट हिन्दी-गुजराती टीचर , ગૌરવ, ૩૪
- Snell 2003 , str. 17
- Bahri 2004 , s. (xiii)
- Snell 2003 , str. 18
- Pozorováno v Huet 2007 pro ॠ a ऌ
- Snell 2003 , s. 8
- Eugène Burnouf , O literatuře Tibetu, výňatek z č. Vii Quarterly Oriental magazine v Kalkatě , Asian Journal , sv. 10, 1827, s. 131
{kind=link}
Bibliografie
- (fr) Akshay Bakaya, Malá psací kniha v hindštině , Larousse, 2017
- (en) Hardev Bahri , Learners 'Hindi-English Dictionary , Rajpal,2004, 758 s. ( ISBN 81-7028-002-8 , číst online ) , „Tipy na výslovnost a psaní v hindštině“
- (en) Florian Coulmas , Writing Systems , Cambridge University Press,2003, 270 s. ( ISBN 0-521-78737-8 , číst online ) , „Začlenění samohlásky - Devanagari“
- (en) Girish Dalvi , „ Anatomy of Devanagari Typefaces “ , Myšlenky na design ,ledna 2009, str. 30-36 ( číst online )
- (en) Yashodeep Gholap , Designing a Devanāgarī text font for newspaper use , coll. "Den typografie 2012",2012( číst online )
- Gérard Huet , Heritage of Sanskrit Dictionary Sanskrit-francouzština ,20. května 2007( číst online )
- (en) HM Lambert , Introduction to Devanagari Script for Students of Sanskrit, Hindi, Marathi, Gujarati and Bengali , Oxford University Press,1953
- Annie Montaut a Akshay Bakaya , Le hindština sans smutek , Assimil ,1994( ISBN 2-7005-0172-1 ) , „Psaní a zvuky hindštiny“
- Annie Montaut a Sarasvati Joshi , Parlons hindi , Paříž / Montreal (Quebec), L'Harmattan,1999, 281 s. ( ISBN 2-7384-8135-3 , číst online ) , „Zvuky a písmena“
- (en) Bapurao S. Naik , Typografie Devanagari , Bombay, Ředitelství jazyků,1971
- (en) Rupert Snell , Naučte se hindsky , Naučte se,2003( ISBN 0-340-86687-X ) , „Hindi script and sound system“
- (gu) સુરેશચંદ્ર જ. દવે , મનસુખ કે. મોલિયા , મોહિની આચાર્ય a મહારુદ્ર કે. શર્મા , સંસ્કૃત: ધોરણ 10 , ગુજરાત રાજ્ય શાળા પાઠ્યપુસ્તક મંડળ,2006( číst online )Sanskrtský učební manuál
Podívejte se také
Související články
- Tabulka znaků Unicode - dévanâgarî
- Tabulka znaků Unicode - devanâgarî - rozšířená
- Přepis devanagari
- Přepis indických jazyků
- Indická písma a informatika